LiSA – Listen, See and Act: fusing audio-video cues to perceive visible and invisible events and develop perception-to-action solutions for autonomous vehicles

Keywords: Multi-modal systems – driverless vehicles – audio/visual perception – perception-to-action – deep learning – deep reinforcement learning
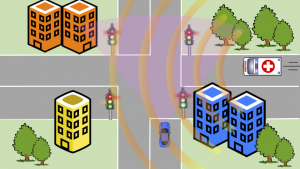
Project Summary: The development of a more circular economy is a key stepstone to reduce the environmental impact of the production and distribution systems, guarantee supply chains of strategic material and favour economic growth. In this context, transportation services play a crucial role and enhancing them to favour sustainability, inclusiveness and safety is fundamental. To this aim, transportation systems are experiencing a deep revolution and new mobility paradigms are currently being devised, with several successful solutions that have already been demonstrated. Most of the advancements in transportation systems have been made possible by Artificial Intelligence (AI) methodologies, which facilitated the development of autonomous vehicles (AVs). However, despite the impressive results demonstrated, there are still many open challenges that prevent AVs to be fully integrated into mobility services. Most of the limitations that affect these systems are related to the capability to effectively perceive the entities and the events of the environment and compute timely navigation and reaction commands. Besides hindering the robustness of the overall navigation routines and, therefore, reducing the actual possibility to deploy AVs, these limitations have a significant impact on how people perceive their reliability. Inspired by the previous considerations, this proposal aims to empower AVs with novel perception-to-action capabilities that rely on multiple and heterogeneous data sources. In particular, the combination of visual and audio information allows computing a more robust, efficient, and descriptive representation of the vehicle’s surroundings. The key intuition behind the proposed solution draws inspiration from human behaviour. While driving, humans greatly rely on auditory perception to predict and localise events which cannot be directly observed (e.g., a siren of an ambulance approaching an intersection). Hearing, indeed, is able to provide omnidirectional perception, overcoming the limitations imposed by occlusions, and, thus, enhancing the driver’s awareness of the scene. Being able to predict the occurrence of visual events long before they can actually be seen means increasing the driver’s “time allowance” to properly react to those events. Such allowance is even more significant in the case of AVs, operating both in a full or semi-autonomy regime. Yet, the use of sound is greatly under-investigated in the intelligent transportation systems community and driverless vehicles are, still, largely deaf.
This project aims to tackle this problem by:
- Detecting and localising acoustic events in urban scenarios.
- Generating joint representation of audio/visual events to enable the development of multi-modal systems that model spatiotemporal relationships of audio/visual inputs.
- Developing perception-to-action methodologies to map audio-visual cues to vehicle control commands and improve autonomous navigation capabilities.
Scientific publications
D-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles
Authors
Alberto Dionigi, Simone Felicioni, Mirko Leomanni, and Gabriele Costante
Abstract
Visual active tracking is a growing research topic in robotics due to its key role in applications such as human assistance, disaster recovery, and surveillance. In contrast to passive tracking, active tracking approaches combine vision and control capabilities to detect and actively track the target. Most of the work in this area focuses on ground robots, while the very few contributions on aerial platforms still pose important design constraints that limit their applicability. To overcome these limitations, in this letter we propose D-VAT, a novel end-to-end visual active tracking methodology based on deep reinforcement learning that is tailored to micro aerial vehicle platforms. The D-VAT agent computes the vehicle thrust and angular velocity commands needed to track the target by directly processing monocular camera measurements. We show that the proposed approach allows for precise and collision-free tracking operations, outperforming different state-of-the-art baselines on simulated environments which differ significantly from those encountered during training. Moreover, we demonstrate a smooth real-world transition to a quadrotor platform with mixedreality.
Publication venue
IEEE Robotics and Automation Letters (RA-L) – link
Video
Citation
@article{dionigi2024dvat,
author={Dionigi, Alberto and Felicioni, Simone and Leomanni, Mirko and Costante, Gabriele}, journal={IEEE Robotics and Automation Letters}, title={D-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles}, year={2024}, volume={}, number={}, pages={1-8}, keywords={Target tracking;Cameras;Visualization;Robots;Angular velocity;Training;Aerospace electronics;Visual Tracking;Reinforcement Learning;Visual Servoing;Aerial Systems: Applications}, doi={10.1109/LRA.2024.3385700}}
The Power of Input: Benchmarking Zero-Shot Sim-To-Real Transfer of Reinforcement Learning Control Policies for Quadrotor Control
Authors
Alberto Dionigi, Gabriele Costante, Giuseppe Loianno
Abstract
In the last decade, data-driven approaches have become popular choices for quadrotor control, thanks to their ability to facilitate the adaptation to unknown or uncertain flight conditions. Among the different data-driven paradigms, Deep Reinforcement Learning (DRL) is currently one of the most explored. However, the design of DRL agents for Micro Aerial Vehicles (MAVs) remains an open challenge. While some works have studied the output configuration of these agents (i.e., what kind of control to compute), there is no general consensus on the type of input data these approaches should employ. Multiple works simply provide the DRL agent with full state information, without questioning if this might be redundant and unnecessarily complicate the learning process, or pose superfluous constraints on the availability of such information in real platforms. In this work, we provide an in-depth benchmark analysis of different configurations of the observation space. We optimize multiple DRL agents in simulated environments with different input choices and study their robustness and their sim-to-real transfer capabilities with zero-shot adaptation. We believe that the outcomes and discussions presented in this work supported by extensive experimental results could be an important milestone in guiding future research on the development of DRL agents for aerial robot tasks.
Publication venue
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024) – link
Video
LF2SLAM: Learning-based Features For visual SLAM
Authors
Marco Legittimo, Francesco Crocetti, Mario Luca Fravolini, Giuseppe Mollica, Gabriele Costante
Abstract
Autonomous robot navigation relies on the robot’s ability to understand its environment for localization, typi- cally using a Visual Simultaneous Localization And Mapping (SLAM) algorithm that processes image sequences. While state-of-the-art methods have shown remarkable performance, they still have limitations. Geometric VO algorithms that leverage hand-crafted feature extractors require careful hyper- parameter tuning. Conversely, end-to-end data-driven VO al- gorithms suffer from limited generalization capabilities and require large datasets for their proper optimizations. Recently, promising results have been shown by hybrid approaches that integrate robust data-driven feature extraction with the geometric estimation pipeline. In this work, we follow these intuitions and propose a hybrid VO method, namely Learned Features For SLAM (LF^2SLAM), that combines a deep neural network for feature extraction with a standard VO pipeline. The network is trained in a data-driven framework that includes a pose estimation component to learn feature extractors that are tailored for VO tasks. A novel loss function modification is introduced, using a binary mask that considers only the infor- mative features. The experimental evaluation performed shows that our approach has remarkable generalization capabilities in scenarios that differ from those used for training. Furthermore, LF^2SLAM exhibits robustness in more challenging scenarios, i.e., characterized by the presence of poor lighting and low amount of texture, with respect to the state-of-the-art ORB- SLAM3 algorithm.
Publication venue
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2024) – link
Video
Knowing When and Where Improves Acoustic Classification. A Different Perspective on Auditory Contextual Information
Authors
Katerina Vinciguerra, Letizia Marchegiani
Abstract
Autonomous vehicles must be safe. A safe vehicle is a vehicle that can accurately and robustly understand the environment and sensibly decide what to do next. Driverless systems rely on several sensors to perceive their surroundings, combining their characteristics and differences in a mutually beneficial way. Audio has been long overlooked in this context, even though it can provide information which is crucial for safety (e.g., the siren of an emergency vehicle approaching from far and that cannot be seen). The consequence is that only a few sound-based datasets are available, which, in return, further limits investigations in the area. This paper aims to demonstrate that, even when dealing with unbalanced and/or not too-big datasets, there might be hidden information to be used and which could greatly enhance the power of those datasets. In particular, we aim to prove that contextual information, meant as the type of place where and the time of the day when a sound is heard, can significantly ease its identification. By relying on a simple Convolutional Neural Network, we show that contextual information, even when coarse, can increase the accuracy of an acoustic object detector up to 85%.
Publication venue
TechRxiv – link
Video (N/A)